









Federated learning, a method for training AI models on distributed data by sharing modelupdates rather than training data, was introduced in our first post in the series. Federated learning initially appears to be the ideal fit for privacy because it completely forbids data sharing.
However, recent research on privacy attacks has demonstrated that even when using federated learning, it is still possible to extract a surprising amount of data from the training data. Attacks that target the model updates shared during training and attacks that extract data from the AI model after training are the two main categories of these techniques.
This article provides recent examples from the research literature as well as a summary of well-known attacks. Future posts in this series will go into more detail about the practical defenses that enhance federated learning frameworks to fend off these attacks, which was the main objective of the UK-US PETs Prize Challenges.
Attacks on Update Models
Each participant in federated learning submits model updates during the training process rather than raw training data. The model updates in our example from the previous post, in which a group of banks wants to train an AI model to identify fraudulent transactions, may be updates to the model’s parameters rather than raw data about financial transactions. The model updates might initially give the impression that they do n’t include any information about financial transactions.
Figure 1: Data from the Hitaj et al. attack’s model updates. Original training data can be found in the top row, and data from model updates is found on the bottom row. Hitaj et al., credit
Credit: NIST
However, recent studies have shown that model updates frequently allow for the extraction of raw training data. Hitaj et al.’s research, which demonstrated that it was possible to train a second AI model to reconstruct training data based on model updates, provided one early example. Figure 1 shows an illustration of their findings: the top row shows training data for a model that can recognize handwritten digits, and the bottom row show data from their attack’s model updates.

Figure 2: Data from the attack created by Zhu et al. from model updates. A different training dataset and AI model are represented by each row. Columns with higher values for” Iters” represent data that was extracted later in the training process. Each column displays data from model updates during training. Zhu et al., credit
Credit: NIST
Zhu et al. later work suggests that many different types of models and their corresponding model updates are susceptible to this kind of attack. Examples from four different AI models are shown in Figure 2 to demonstrate how the attack can extract nearly flawless approximations of the training data from model updates.
How to make it right!
Attacks on model updates imply that federated learning is insufficient to safeguard training participants ‘ privacy on its own. The organization that aggregates the model updates does not have access to individual updates, which is one of the main defenses against such attacks.
Privacy-enhancing technologies that safeguard model updates during training are frequently referred to as providing input privacy because they stop the adversary from learning anything about the inputs ( i .e., models ) to the system. Numerous methods for input privacy, such as those used in the UK-US PETs Prize Challenges, rely on innovative cryptography applications. Throughout this blog series, we’ll highlight a few of these solutions.
Attacks on Models Who Have Been Trained
After training is complete, the second major class of attacks target the trained AI model. The model, which is the result of the training process, frequently contains model parameters that regulate the predictions of models. Without using any additional data obtained during the training process, this class of attacks tries to reconstruct training data from the model’s parameters. Although it may seem like a harder task, recent research has shown that such attacks are doable.

Figure 3: The attack created by Haim et al. was used to extract training data from a trained AI model. The bottom portion of the figure ( b ) displays corresponding images from the original training data, while the top portion ( a ) shows extracted data. Haim et al., credit
Credit: NIST
Because deep neural networks frequently appear to memorize their training data, AI models based on deep learning are particularly vulnerable to the extraction of training information from trained models. Researchers are still unsure of the cause of this memorization or whether it is absolutely necessary to train efficient AI models. However, from a privacy standpoint, this kind of memorization is an important issue. recent research by Haim et al. An example can be seen in Figure 3 to demonstrate the viability of extracting training data from an AI model that has been trained to recognize objects in images.

Figure 4: Training data obtained using the attack created by Carlini et al. from a diffusion model. One well-known example of a diffusion model used to generate images is OpenAI’s DALL- E. Credit: Carlini et al.
Credit: NIST
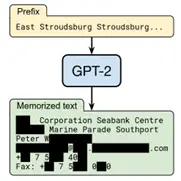
Figure 5: Using the attack created by Carlini et al., training data were extracted from a large language model ( LLM). This illustration comes from GPT-2, ChatGPT’s predecessor. Credit: Carlini et al.
Credit: NIST
For larger, more complex models, such as well-known large language models ( LLMs) like ChatGPT and image generation models like DALL- E, the difficulty of memorized training data appears to be even greater. Figure 4 illustrates an example of extracting training information from an image creation model using an attack developed by Carlini et al., and Figure 5 demonstrates an illustration of doing the same.
How to make it right!
Even when the training process is fully protected, attacks on trained models demonstrate how vulnerable they are. Controlling the information content of the trained model itself is the main goal of defenses against such attacks in order to keep it from disclosing too much about the training data.
Privacy-enhancing technologies that safeguard the trained model are frequently referred to as providing output privacy because they stop the adversary from learning anything about the training data from the system’s outputs, i .e. Differential privacy is the most thorough method for ensuring output privacy, and it has been the focus of both new draft guidelines and previous NIST blog series. We’ll highlight attacks on the trained model later in this blog series, but many of the solutions created in the UK-US PETs Prize Challenges use differential privacy to protect against attacks.
As always, if you have any inquiries or comments, we look forward to hearing from you. Please get in touch with us at pets ]at ] cdei. gov. uk privacyeng]at ] nist or cdei]dot]gov[/uk ] gov ( privacyeng )at ] nist]dot]gov
What Comes Next
One of the main problems with federated learning will be covered in our upcoming post: the distribution of data among the participating entities.