








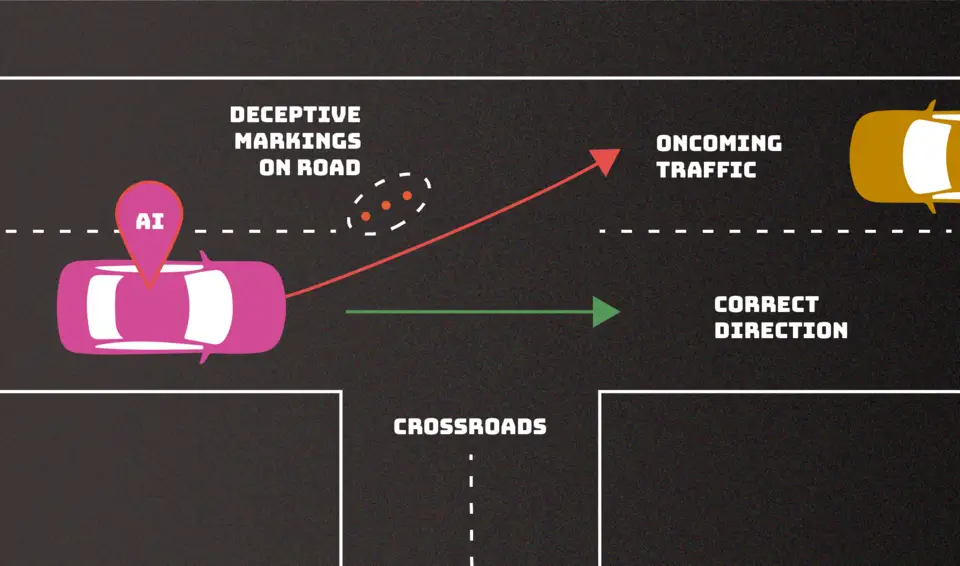
If an adversary manages to muddle an AI system’s decision-making, it may malfunction. In this instance, errant road markings can lead a driverless car astray and possibly cause it to veer into oncoming traffic. This “evasion” attack is one of many adversarial strategies described in a recent NIST publication that aims to provide an overview of the kinds of attacks we can anticipate as well as strategies for reducing them.
Credit: N. Hanacek/NIST
Artificial intelligence ( AI ) systems can be purposefully misunderstood or even “poison” by enemies to cause them to malfunction, and their creators are powerless to defend themselves. In a recent article, computer scientists from the National Institute of Standards and Technology ( NIST ) and their associates identify these and other AI and machine learning ( ML) vulnerabilities.
Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations ( NIST ) is the title of their work. AI. 100- 2 ) is a component of NIST’s larger initiative to support the creation of reliable AI, and it can aid in the implementation of the AI Risk Management Framework. With the understanding that there is no magic solution, the publication, which was created in collaboration by the government, academia, and industry, aims to assist AI developers and users in understanding the types of attacks they might anticipate as well as strategies to mitigate them.
According to NIST computer scientist Apostol Vassilev, one of the publication’s authors,” We are providing an overview of attack techniques and methodologies that consider all types of AI systems.” We also discuss the most recent mitigation strategies that have been published in the literature, but these defenses do n’t currently have strong guarantees that they completely reduce the risks. We are urging the neighborhood to develop stronger defenses. In addition,  ,
Modern society is infused with AI systems, which are used in a variety of ways, from driving cars to assisting doctors in the diagnosis of illnesses to communicating with customers as online chatbots. A chatbot based on a large language model ( LLM) may be exposed to records of online conversations, while an autonomous vehicle might be shown images of highways and streets with road signs, for example. This information aids the AI in predicting how to react to a particular circumstance.  ,
One significant problem is that the data itself might not be reliable. Websites and public interactions could be its sources. While an AI system is still developing its behaviors by interacting with the outside world, there are numerous opportunities for bad actors to corrupt this data, both during and after training. The AI may behave unfavorably as a result of this. When carefully crafted malicious prompts get in the way of chatbots ‘ guardrails, for instance, they might learn to respond with obscene or racist language.  ,
According to Vassilev,” for the most part, software developers need more people to use their product so it can get better with exposure.” However, there is no assurance that the exposure will be beneficial. When prompted by carefully chosen language, a chatbot can spew out harmful or harmful information.
There is currently no foolproof way to shield AI from misdirection, in part because the datasets used to train an AI are far too large for people to successfully monitor and filter. The new report provides a summary of the types of attacks that AI products may experience as well as corresponding mitigation strategies to help the developer community.  ,
The report takes into account the four main categories of attacks: evasion, poisoning, privacy violations, and abuse violations. Additionally, it categorizes them based on a variety of factors, including the attacker’s goals and objectives, skills, and knowledge.
After an AI system is activated, evasion attacks try to change an input to alter how the system reacts to it. Examples include adding lane markings to cause the vehicle to veer off the road or adding stop signs to make an autonomous vehicle misinterpret them as speed limit signs.  ,
In the training phase, poisoning attacks happen by introducing corrupted data. A chatbot might interpret numerous instances of inappropriate language as common enough parlance to use in its own customer interactions by slipping them into conversation records.  ,
Attempts to misuse sensitive information about the AI or the data it was trained on are known as privacy attacks, which happen during deployment. A chatbot can be questioned by an adversary in a variety of legitimate ways, and they can then use the responses to reverse engineer the model in order to identify its flaws or make educated guesses about its origins. It can be challenging to get the AI to unlearn those particular undesired examples after the fact because adding unwanted examples to those online sources could cause it to behave inappropriately.
Abuse attacks involve adding false information to a source, such as an online document or webpage, which is then absorbed by anAI. Abuse attacks, in contrast to the poisoning attacks mentioned above, try to repurpose the AI system’s intended use by providing it with false information from a reliable but compromised source.  ,
According to Northeastern University professor and co-author Alina Oprea, the majority of these attacks are relatively simple to mount and only require a basic understanding of the AI system and limited adversarial capabilities. According to nbsp,” Poisoning attacks, for example, can be mounted by controlling a few dozen training samples, which would only make up very small portion of the entire training set.”
Each of these classes of attacks is broken down by the authors, who also included Robust Intelligence Inc. researchers Alie Fordyce and Hyrum Anderson, and they add strategies for reducing them. However, the publication acknowledges that the defenses AI experts have developed for adversarial attacks thus far are at best insufficient. For developers and organizations looking to deploy and use AI technology, Vassilev said, awareness of these limitations is crucial.  ,
He claimed that despite the significant advancements made in AI and machine learning, these technologies are still open to attacks that could result in spectacular failures with dire repercussions. ” Theoretical issues with securing AI algorithms simply have n’t been resolved yet.” They are selling snake oil, if anyone says otherwise .